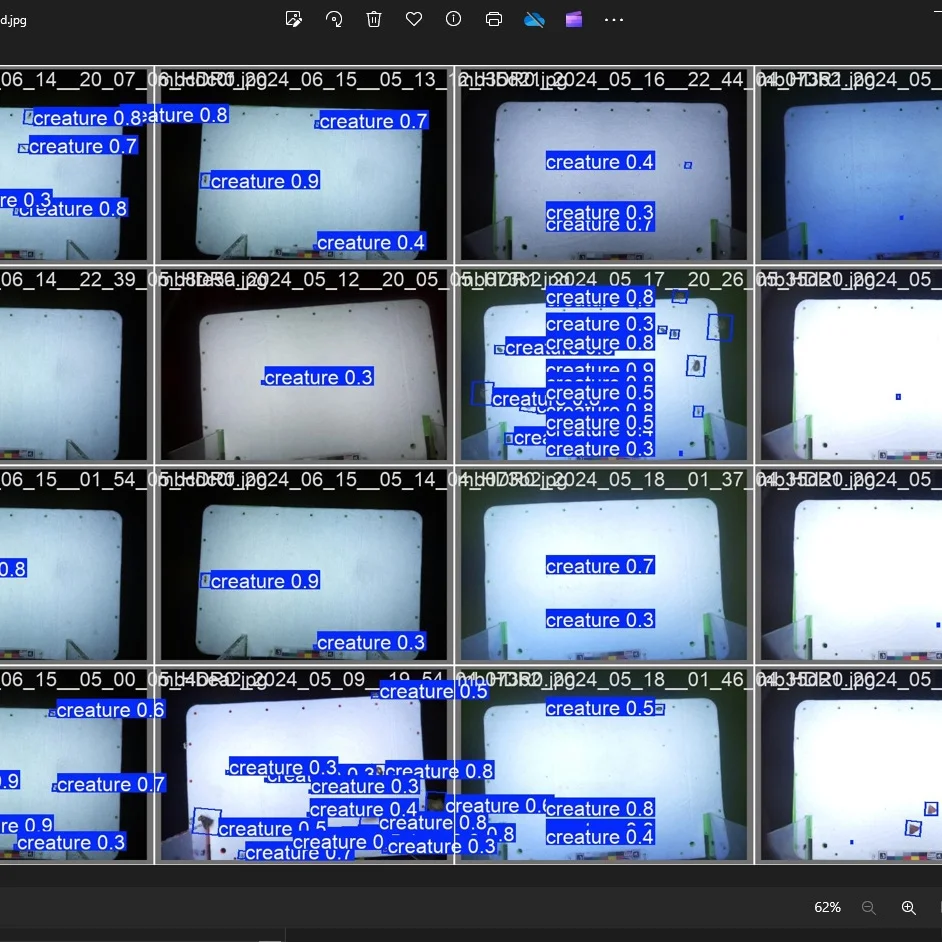
So the mothbox deployment is going great! But now we’re running into the next set of problems.
We are getting like 20 gigs a night from our field team of photos of targets that may or may not have moths on them.
They are in somewhat remote places and don’t have the best internet always.
The long-term goal is to make some software that can look through all the photos and try to ID all the moths as best as it can.
But the short-term goal is just to make some much more simple software that just learns what backgrounds look like, And segments out things that aren’t the background (i.e. insect visitors).
So basically look at thousands of photos like these, and reliably cut out small cropped photos of all the insects.

This should be quite doable by training several different open computer vision models like YOLO
And I’ve done things like this with online things like roboflow or colab, But I need an offline solution.
This requires installing a local version of YOLO, And having a local offline annotation software (which are increasingly hard to find, Right now we are using X-anylabelling).
And then pointing YOLO towards a correctly organized set of folders that hold the training data and the labeled data. This is the part I tend to get lost in
This is all so that our field techs could try to run this on their own without having to upload hundreds of gigs of data to something like RoboFlow first.
If anyone out there has gone through this and can help give me just a very straightforward walkthrough like:
-Type these commands and install YOLO.
-Put all of your blank images without insects in a folder like this
-
label a bunch of files with images, And put them in a folder like this
-
now run this command to train YOLO
-
now run this command to give YOLO new photos and see if it works.
-
All of your cropped insect images will be in a folder like this…